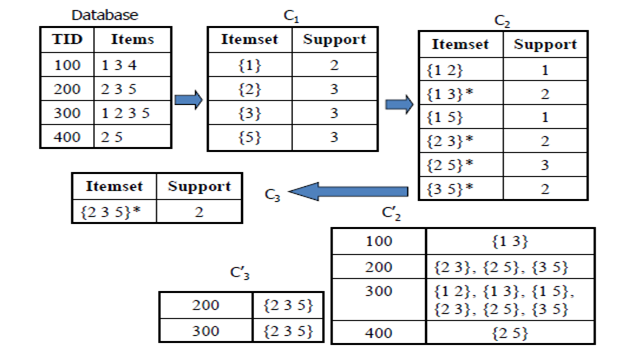
每个事务都被视为一组项(项集)。给出一个门槛 C,Apriori算法识别至少是子集的项集 C 数据库中的事务。Apriori使用“自下而上”方法,其中频繁的子集一次扩展一个项目(称为候选生成的步骤),并且针对数据测试候选组。当没有找到进一步成功的扩展时,算法终止。
2. Python编程实现Apriori算法
2.1. Apriori算法步骤
S1.令 k=1
S2.扫描数据库,生成长度为k的候选项集的集合Ck
S3.重复S4~S8直到找不到新的候选项集的集合Ck
S4.从长度为k的频繁项集Lk生成长度为(k + 1)的候选项集
S5.修剪长度为(k + 1)的候选项集中的出现频率低于(min_support阈值)的候选项目
S6.通过扫描数据库,统计每个候选项的数目
S7.删除出现频率低于(min_support阈值)的候选项,只留下频繁出现的候选项目集Lk
S8. k = k + 1
2.2. 生成长度为1的候选项集C1
1 2 3 4 5 6 7 8 9 10
# C1 是大小为1的所有候选项集的集合 defcreateC1(dataSet): C1 = [] for transaction in dataSet: for item in transaction: ifnot [item] in C1: C1.append([item]) #store all the item unrepeatly # C1.sort() #return map(frozenset, C1)#frozen set, user can't change it. returnlist(map(frozenset, C1))
2.3. 扫描数据库,返回频繁出现的候选项目集Lk(出现频率大于给定阈值minSupport)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defscanD(D, Ck, minSupport): ssCnt={} for tid in D: for can in Ck: if can.issubset(tid): #if not ssCnt.has_key(can): ifnot can in ssCnt: ssCnt[can]=1 else: ssCnt[can]+=1 numItems=float(len(D)) retList = [] supportData = {} for key in ssCnt: support = ssCnt[key]/numItems #compute support if support >= minSupport: retList.insert(0, key) supportData[key] = support return retList, supportData
2.4. apriori组合,向上合并L
1 2 3 4 5 6 7 8 9 10 11
defaprioriGen(Lk, k): #creates Ck 参数:频繁项集列表 Lk 与项集元素个数 k retList = [] lenLk = len(Lk) for i inrange(lenLk): for j inrange(i+1, lenLk): #两两组合遍历 L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2] L1.sort(); L2.sort() if L1 == L2: #若两个集合的前k-2个项相同时, 则将两个集合合并 retList.append(Lk[i] | Lk[j]) #set union return retList
2.5. apriori算法核心函数
1 2 3 4 5 6 7 8 9 10 11 12 13
defapriori(dataSet, minSupport = 0.5): C1 = createC1(dataSet) D = list(map(set, dataSet)) #python3 L1, supportData = scanD(D, C1, minSupport)#单项最小支持度判断 0.5,生成L1 L = [L1] k = 2 while (len(L[k-2]) > 0):#创建包含更大项集的更大列表, 直到下一个大的项集为空 Ck = aprioriGen(L[k-2], k)#Ck Lk, supK = scanD(D, Ck, minSupport)#get Lk supportData.update(supK) L.append(Lk) k += 1#继续向上合并 生成项集个数更多的 return L, supportData