![]()
1. 集成学习AdaBoost算法简介
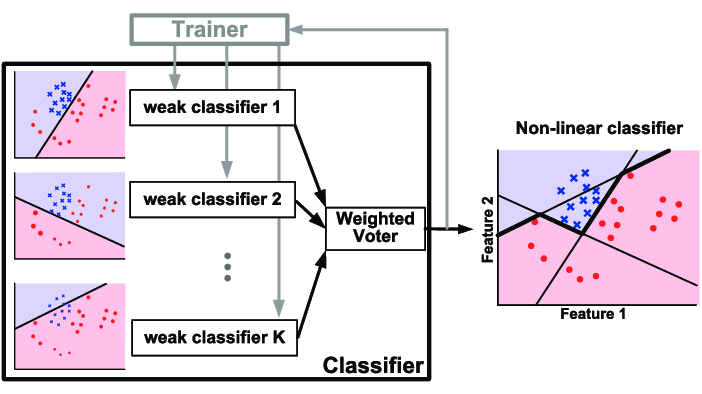
AdaBoost全称是adaptive boosting,该算法基本思想:多个结构较为简单,分类或预测精度较低的弱学习算法可以通过某种方式结合成具有较强学习能力的强学习算法。根据统计学习方法的三要素,AdaBoost 方法=加法模型+指数损失函数(策略)+前向分步 算法。
2. AdaBoost运行原理如下:
3. Python编程实现基于单层决策树的AdaBoost算法
3.1. 基于单层决策树的AdaBoost算法步骤
- S1.找出最佳单层决策树: a.将最小分类误差率minerror=inf b.对数据集中的每一个特征: c.对该特征的每个步长(找出决策阈值): d.对每个不等号(>=,<): e.建立一颗单层决策树(只包含树桩)并利用加权数据集并计算该决策树的分类误差率 f.如果分类误差率小于minerror,则将当前单层决策树设置成最佳单层决策树。
- S2.利用单层决策树的分类误差率计算该决策树的比例系数alpha
- S3.计算更新权重向量D
- S4.更新累计类别估计值,计算AdaBoost模型的错误率
- S5.如果错误率为0或者分类器数目i>M,则退出循环
3.2. 寻找最优决策树
找到加权错误率(分类错误率)最小的单层决策树(会被不断迭代)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def buildStump(dataArray, classLabels, D):
dataMatrix = np.mat(dataArray); labelMat = np.mat(classLabels).T
m, n = np.shape(dataMatrix)
stepNum = 10.0; bestStump = {}; bestClassEst = np.mat(np.zeros((m, 1)))
minError = np.inf
for i in range(n):
rangeMin = dataMatrix[:, i].min(); rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin)/stepNum
for j in range(-1, int(stepNum)+1):
for thresholdIneq in ['lt', 'gt']:
thresholdValue = rangeMin + float(j) * stepSize
predictClass = stumpClassify(dataMatrix, i, thresholdValue, thresholdIneq)
errArray = np.mat(np.ones((m, 1)))
errArray[predictClass == labelMat] = 0
weightError = D.T * errArray
if weightError < minError:
minError = weightError
bestClassEst = predictClass.copy()
bestStump['dimen'] = i
bestStump['thresholdValue'] = thresholdValue
bestStump['thresholdIneq'] = thresholdIneq
return bestClassEst, minError, bestStump
|
3.3. 输出多个弱分类器的数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def adaBoostTrainDS(dataArray, classLabels, numIt=40):
weakClass = []
m, n = np.shape(dataArray)
D = np.mat(np.ones((m, 1))/m)
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(numIt):
print("i:", i)
bestClassEst, minError, bestStump = buildStump(dataArray, classLabels, D)
print("D.T:", D.T)
alpha = float(0.5*np.log((1-minError)/max(minError, 1e-16)))
print("alpha:", alpha)
bestStump['alpha'] = alpha
weakClass.append(bestStump)
print("classEst:", bestClassEst)
expon = np.multiply(-1*alpha*np.mat(classLabels).T, bestClassEst)
D = np.multiply(D, np.exp(expon))
D = D/D.sum()
aggClassEst += alpha*bestClassEst
print("aggClassEst:", aggClassEst.T)
print(np.sign(aggClassEst) != np.mat(classLabels).T)
aggError = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m, 1)))
print("aggError", aggError)
aggErrorRate = aggError.sum()/m
print("total error:", aggErrorRate)
if aggErrorRate == 0.0: break
return weakClass
|
3.4. 输出分类结果
1
2
3
4
5
6
7
8
9
10
| def adaTestClassify(dataToClassify, weakClass):
dataMatrix = np.mat(dataToClassify)
m =np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(len(weakClass)):
classEst = stumpClassify(dataToClassify, weakClass[i]['dimen'], weakClass[i]['thresholdValue'], weakClass[i]['thresholdIneq'])
aggClassEst += weakClass[i]['alpha'] * classEst
print('第', i, '个弱分类器权值:', aggClassEst)
return np.sign(aggClassEst)
|
3.5. 主函数
1
2
3
4
5
6
7
8
9
10
11
12
|
if __name__ == '__main__':
D =np.mat(np.ones((5, 1))/5)
dataMatrix, classLabels = loadSimData()
bestClassEst, minError, bestStump = buildStump(dataMatrix, classLabels, D)
weakClass = adaBoostTrainDS(dataMatrix, classLabels, 9)
testClass = adaTestClassify(np.mat([0, 0]), weakClass)
print('最终分类标签:', testClass)
|
运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| D.T: [[0.2 0.2 0.2 0.2 0.2]]
alpha: 0.6931471805599453
classEst: [[-1.]
[ 1.]
[-1.]
[-1.]
[ 1.]]
aggClassEst: [[-0.69314718 0.69314718 -0.69314718 -0.69314718 0.69314718]]
[[ True]
[False]
[False]
[False]
[False]]
aggError [[1.]
[0.]
[0.]
[0.]
[0.]]
total error: 0.2
i: 1
D.T: [[0.5
0.125 0.125 0.125 0.125]]
alpha: 0.9729550745276565
classEst: [[ 1.]
[ 1.]
[-1.]
[-1.]
[-1.]]
aggClassEst: [[ 0.27980789 1.66610226 -1.66610226 -1.66610226 -0.27980789]]
[[False]
[False]
[False]
[False]
[ True]]
aggError [[0.]
[0.]
[0.]
[0.]
[1.]]
total error: 0.2
i: 2
D.T: [[0.28571429 0.07142857 0.07142857 0.07142857 0.5 ]]
alpha: 0.8958797346140273
classEst: [[1.]
[1.]
[1.]
[1.]
[1.]]
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
[[False]
[False]
[False]
[False]
[False]]
aggError [[0.]
[0.]
[0.]
[0.]
[0.]]
total error: 0.0
第 0 个弱分类器权值: [[-0.69314718]]
第 1 个弱分类器权值: [[-1.66610226]]
第 2 个弱分类器权值: [[-2.56198199]]
最终分类标签: [[-1.]]
|