![]()
1. 在Linux系统安装Python及数据处理所需的numpy、pandas库
之前尝试手动下载numpy库,解压,然后按提示安装,却发现numpy库依赖上级库nose,又下载nose库,但在手动安装pandas库时出错…后发现可通过pip的简单方式安装,自动解决依赖,相比于需要手动下载安装上级依赖的手动安装方式更方便,安装代码如下
1
2
3
4
5
6
7
8
| sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy //安装Numpy库:提供数组支持,以及相应的高效的处理函数
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple SciPy //安装SciPy库:提供矩阵支持,以及矩阵相关的数值计算模块
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib //安装Matplotlib库:强大的数据可视化工具、作图库
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas //安装Pandas库:强大、灵活的数据分析和探索工具
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple statsmodels //安装StatsModels库:统计建模和计量经济学,包括描述统计、统计模型估计和推断
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn //安装Scikit-Learn库:支持回归、分类、聚类等强大的机器学习库
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple keras //安装Keras库:深度学习库,用于建立神经网络以及深度学习模型
sudo pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim //安装Gensim库:用来做文本主题模型的库,可能用于文本挖掘
|
2. 数据加载
使用python的pandas库提供的数据处理支持,读取特定文件中庞大数据到到程序的运行内存中以便进行处理。如读取存放于“Train_UWu5bXk.csv”文件中的Bigmart销售数据到变量data中,代码如下:
1
2
3
4
5
6
7
| import pandas as pd
print("数据加载:\n")
variables=['Item_Identifier', 'Item_Weight', 'Item_Fat_Content', 'Item_Visibility', 'Item_Type', 'Item_MRP', 'Outlet_Identifier', 'Outlet_Establishment_Year', 'Outlet_Size', 'Outlet_Location_Type', 'Outlet_Type', 'Item_Outlet_Sales']
data = pd.read_csv('Train_UWu5bXk.csv', sep=',', engine='python', header=None, skiprows=1, names=variables)
|
3. 粗略查看数据规模分布等信息
通过上一步数据加载已经成功加载了Bigmart销售数据,接下来先粗略了解Bigmart销售数据的矩阵规模信息,然后再根据信息对销售数据有粗略认识,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
print("\n查看各字段的信息")
data.info()
print('\n数据粗略查看:')
list_view = data.describe()
list_view.loc['jicha'] = list_view.loc['max'] - list_view.loc['min']
list_view.loc['bianyixishu'] = list_view.loc['std']/list_view.loc['mean']
list_view.loc['sifenweijianju'] = list_view.loc['75%'] - list_view.loc['25%']
print(list_view)
print('\n输出每个列丢失值也即值为NaN的数据和,并从多到少排序:')
total = data.isnull().sum().sort_values(ascending=False)
percent =(data.isnull().sum()/data.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
print(missing_data)
|
显示“Train_UWu5bXk.csv”文件中的Bigmart销售数据粗略信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| 查看各字段的信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8523 entries, 0 to 8522
Data columns (total 12 columns):
Item_Identifier 8523 non-null object
Item_Weight 7060 non-null float64
Item_Fat_Content 8523 non-null object
Item_Visibility 8523 non-null float64
Item_Type 8523 non-null object
Item_MRP 8523 non-null float64
Outlet_Identifier 8523 non-null object
Outlet_Establishment_Year 8523 non-null int64
Outlet_Size 6113 non-null object
Outlet_Location_Type 8523 non-null object
Outlet_Type 8523 non-null object
Item_Outlet_Sales 8523 non-null float64
dtypes: float64(4), int64(1), object(7)
memory usage: 799.1+ KB
数据粗略查看:
Item_Weight Item_Visibility Item_MRP Outlet_Establishment_Year Item_Outlet_Sales
count 7060.000000 8523.000000 8523.000000 8523.000000 8523.000000
mean 12.857645 0.066132 140.992782 1997.831867 2181.288914
std 4.643456 0.051598 62.275067 8.371760 1706.499616
min 4.555000 0.000000 31.290000 1985.000000 33.290000
25% 8.773750 0.026989 93.826500 1987.000000 834.247400
50% 12.600000 0.053931 143.012800 1999.000000 1794.331000
75% 16.850000 0.094585 185.643700 2004.000000 3101.296400
max 21.350000 0.328391 266.888400 2009.000000 13086.964800
jicha 16.795000 0.328391 235.598400 24.000000 13053.674800
bianyixishu 0.361144 0.780224 0.441690 0.004190 0.782335
sifenweijianju 8.076250 0.067596 91.817200 17.000000 2267.049000
输出每个列丢失值也即值为NaN的数据和,并从多到少排序:
Total Percent
Outlet_Size 2410 0.282764
Item_Weight 1463 0.171653
Item_Outlet_Sales 0 0.000000
Outlet_Type 0 0.000000
Outlet_Location_Type 0 0.000000
Outlet_Establishment_Year 0 0.000000
Outlet_Identifier 0 0.000000
Item_MRP 0 0.000000
Item_Type 0 0.000000
Item_Visibility 0 0.000000
Item_Fat_Content 0 0.000000
Item_Identifier 0 0.000000
|
从以上信息我们可初步了解到”Train_UWu5bXk.csv”文件中的数据的规模为:8523x12。且可看出在12列属性中有些列的数据有缺失如:’产品重量Item_Weight’列(7060,缺失1463, 占17.2%)和’商店覆盖面积Outlet_Size’列(6113,缺失2410, 占28.3%)。对于数据的分布情况,从中可看出:
- 产品重量’Item_Weight’变量:值集为4.555~21.35,均值为:12.857645,方差为4.643456,变异系数为0.361144,四分位间距为8.076250,说明分布较为均匀但数据较分散,存在缺失项(占17.2%)。
- 分配给特定产品的商店中所有产品的总显示区域的百分比’Item_Visibility’变量:值集为0~0.328391,均值为0.066132,方差为0.051598,变异系数为0.780224,四分位间距为0.067596,说明数据较为集中在平均值附近,数据较为紧凑,无缺项。
- 产品的最大零售价’Item_MRP’变量:值集为31.29~266.8884,均值为140.992782,方差为62.275067,变异系数为0.441690,四分位间距为91.817200,数据较分散,无缺项。
- 商店开店年份’Outlet_Establishment_Year’变量:值集为1985~2009,均值为1997.831867,方差为8.371760,变异系数为0.004190,四分位间距为17,数据较紧凑,且无缺项。
- 在特定商店销售产品’Item_Outlet_Sales’(这是要预测的结果变量)
4. 数据清洗
4.1. 缺失值处理
判断缺失值的分布情况:
从上一步粗略查看已知’产品重量Item_Weight’、’商店覆盖面积utlet_Size’两列的数据有缺失。而缺失值处理常用的方法有以下几种:1.直接删除、2.使用一个全局常量填充、3.使用均值或中位数代替、4.插补法(包括:随机插补法、多重插补法、热平台插补、拉格朗日差值法和牛顿插值法)、5.建模法。
- 由数据粗略查看知,’Item_Weight’分布较为均匀但数据较分散,存在缺失项,故决定缺失内容采用均值填补
- 对于商店覆盖面积’Outlet_Size’变量:为有限个字符串变量,故对缺失内容采用出现次数最多的值填补
代码如下:1
2
3
4
5
6
7
|
Item_Weight_mean = data['Item_Weight'].mean()
data['Item_Weight'] = data['Item_Weight'].fillna(Item_Weight_mean)
utlet_Size_mode = data['utlet_Size'].mode()
data['utlet_Size'] = data['utlet_Size'].fillna(utlet_Size_mode[0])
|
5. 异常值处理
调用matplotlib库将各个数据可视化(python中的pyplot),观察异常值
5.1. 产品重量’Item_Weight’
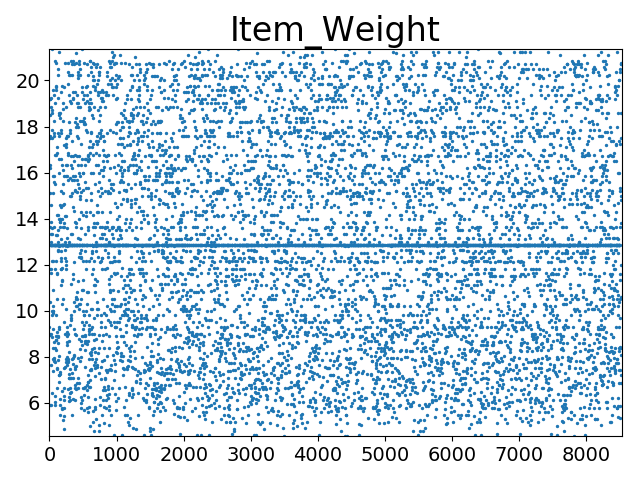
打印’Item_Weight’数据分布散点图代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
x = list(range(0, len(data['Item_Weight'])))
y_Item_Weight = data['Item_Weight']
plt.scatter(x, y_Item_Weight, s=2)
plt.title("Item_Weight", fontsize=24)
plt.tick_params(axis='both', which='major', labelsize=14)
plt.axis([0, len(data['Item_Weight']), min(data['Item_Weight']), max(data['Item_Weight'])])
plt.show()
|
!['Item_Weight'数据分布散点图]()
从图中可看出’Item_Weight’分布较为均匀(5.5~21之间),未发现异常值
5.2. 分配给特定产品的商店中所有产品的总显示区域的百分比’Item_Visibility’
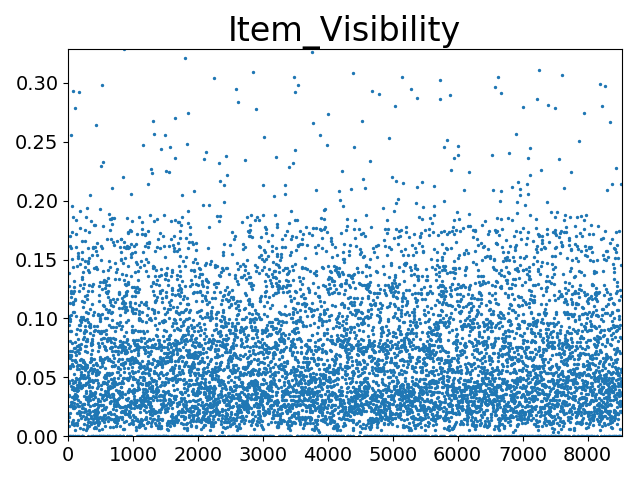
打印’Item_Visibility’数据分布散点图代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
x = list(range(0, len(data['Item_Visibility'])))
y_Item_Visibility = data['Item_Visibility']
plt.scatter(x, y_Item_Visibility, s=2)
plt.title("Item_Visibility", fontsize=24)
plt.tick_params(axis='both', which='major', labelsize=14)
plt.axis([0, len(data['Item_Visibility']), min(data['Item_Visibility']), max(data['Item_Visibility'])])
plt.show()
|
!['Item_Visibility'数据分布散点图]()
从图中可看出’Item_Visibility’分布主要集中于0~0.2区间内,分布随着值增加逐渐稀疏,未发现异常值
5.3. 产品的最大零售价’Item_MRP’
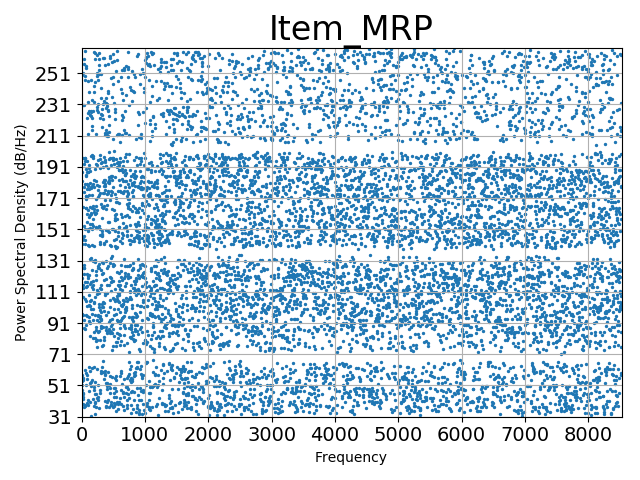
打印’Item_MRP’数据分布散点图代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
x = list(range(0, len(data['Item_MRP'])))
y_Item_MRP = data['Item_MRP']
plt.scatter(x, y_Item_MRP, s=2)
plt.title("Item_MRP", fontsize=24)
plt.tick_params(axis='both', which='both', labelsize=14)
plt.axis([0, len(data['Item_MRP']), min(data['Item_MRP']), max(data['Item_MRP'])])
plt.psd(y_Item_MRP, 10, 10)
plt.show()
|
!['Item_MRP'数据分布散点图]()
从图中可看出’Item_MRP’分布较为阶梯型分布,大致可分为4段(3170, 70135, 135~200, >200),未发现异常值
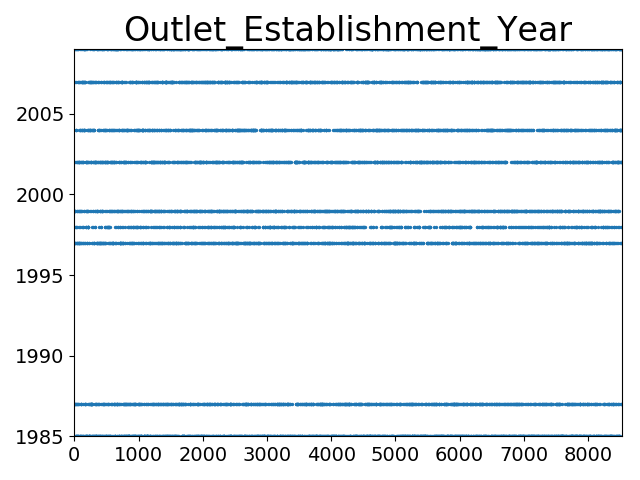
5.3.1. 商店成立年份’Outlet_Establishment_Year’
打印’Outlet_Establishment_Year’数据分布散点图代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
x = list(range(0, len(data['Outlet_Establishment_Year'])))
y_Outlet_Establishment_Year = data['Outlet_Establishment_Year']
plt.scatter(x, y_Outlet_Establishment_Year, s=2)
plt.title("Outlet_Establishment_Year", fontsize=24)
plt.tick_params(axis='both', which='both', labelsize=14)
plt.axis([0, len(data['Outlet_Establishment_Year']), min(data['Outlet_Establishment_Year']), max(data['Outlet_Establishment_Year'])])
plt.show()
|
!['Outlet_Establishment_Year'数据分布散点图]()
从图中可看出’Outlet_Establishment_Year’值集仅有有限几个,值集为1985~2009,未发现异常值
6. 数据转换
将数据中字符串数据映射为数字
6.1. 产品是否低脂肪’Item_Fat_Content’
打印’Item_Fat_Content’数据情况
1
| print(data['Item_Fat_Content'].value_counts())
|
显示’Item_Fat_Content’数据情况
1
2
3
4
5
| Low Fat 5089
Regular 2889
LF 316
reg 117
low fat 112
|
以下代码将’Item_Fat_Content’的字符串值:’Low Fat’,’LF’,’low fat’映射成数字2; 将字符串值:’Regular’, ‘reg’映射成数字1。
1
2
3
4
|
Item_Fat_Content_mapping = {'Regular':int(1), 'reg':int(1), 'Low Fat':int(2), 'LF':int(2), 'low fat':int(2)}
data['Item_Fat_Content'] = data['Item_Fat_Content'].map(Item_Fat_Content_mapping)
data['Item_Fat_Content'] = data['Item_Fat_Content'].fillna(0)
|
6.2. 产品所属的类别 ‘Item_Type’
打印’Item_Type’数据情况
1
| print(data['Item_Type'].value_counts())
|
显示’Item_Type’数据情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Fruits and Vegetables 1232
Snack Foods 1200
Household 910
Frozen Foods 856
Dairy 682
Canned 649
Baking Goods 648
Health and Hygiene 520
Soft Drinks 445
Meat 425
Breads 251
Hard Drinks 214
Others 169
Starchy Foods 148
Breakfast 110
Seafood 64
|
以下代码将’Item_Type’按照出现字符串次数,正序将字符串映射成数字1~16。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Item_Type_mapping = {'Seafood':int(1),
'Breakfast':int(2),
'Starchy Foods':int(3),
'Others':int(4),
'Hard Drinks':int(5),
'Breads':int(6),
'Meat':int(7),
'Soft Drinks':int(8),
'Health and Hygiene':int(9),
'Baking Goods':int(10),
'Canned':int(11),
'Dairy':int(12),
'Frozen Foods':int(13),
'Household':int(14),
'Snack Foods':int(15),
'Fruits and Vegetables':int(16)}
data['Item_Type'] = data['Item_Type'].map(Item_Type_mapping)
data['Item_Type'] = data['Item_Type'].fillna(0)
|
6.3. 唯一商店ID ‘Outlet_Identifier’
打印’Outlet_Identifier’数据情况
1
| print(data['Outlet_Identifier'].value_counts())
|
显示’Outlet_Identifier’数据情况
1
2
3
4
5
6
7
8
9
10
| OUT027 935
OUT013 932
OUT035 930
OUT046 930
OUT049 930
OUT045 929
OUT018 928
OUT017 926
OUT010 555
OUT019 528
|
以下代码将’Outlet_Identifier’值的字符串中提取数字,并覆盖原先str变量为int。
1
2
3
4
5
6
7
|
def convert_currency(var):
new_value = var.replace('OUT', '')
return int(new_value)
data['Outlet_Identifier'] = data['Outlet_Identifier'].apply(convert_currency)
|
转换后数据
1
2
3
4
5
6
7
8
9
10
11
| 27 935
13 932
46 930
35 930
49 930
45 929
18 928
17 926
10 555
19 528
Name: Outlet_Identifier, dtype: int64
|
6.4. 商店的面积覆盖面积 ‘Outlet_Size’
打印’Outlet_Size’数据情况
1
| print(data['Outlet_Size'].value_counts())
|
显示’Outlet_Size’数据情况
1
2
3
| Medium 5203
Small 2388
High 932
|
以下代码将’Outlet_Size’的字符串值:’Small’映射成数字1; ‘Medium’映射成数字2; 将字符串值:’High’映射成数字3。
1
2
3
4
|
Outlet_Size_mapping = {'Small':int(1), 'Medium':int(2), 'High':int(3)}
data['Outlet_Size'] = data['Outlet_Size'].map(Outlet_Size_mapping)
data['Outlet_Size'] = data['Outlet_Size'].fillna(0)
|
6.5. 商店所在的城市类型 ‘Outlet_Location_Type’
打印’Outlet_Location_Type’数据情况
1
| print(data['Outlet_Location_Type'].value_counts())
|
显示’Outlet_Location_Type’数据情况
1
2
3
| Tier 3 3350
Tier 2 2785
Tier 1 2388
|
以下代码将’Outlet_Location_Type’的字符串值:’Tier 1’映射成数字1; ‘Tier 2’映射成数字2; 将字符串值:’Tier 3’映射成数字3。
1
2
3
4
|
Outlet_Location_Type_mapping = {'Tier 1':int(1), 'Tier 2':int(2), 'Tier 3':int(3)}
data['Outlet_Location_Type'] = data['Outlet_Location_Type'].map(Outlet_Location_Type_mapping)
data['Outlet_Location_Type'] = data['Outlet_Location_Type'].fillna(0)
|
6.6. 出口是一家杂货店还是某种超市 ‘Outlet_Type’
打印’Outlet_Type’数据情况
1
| print(data['Outlet_Type'].value_counts())
|
显示’Outlet_Type’数据情况
1
2
3
4
| Supermarket Type1 5577
Grocery Store 1083
Supermarket Type3 935
Supermarket Type2 928
|
以下代码将’Outlet_Type’的字符串值:’Supermarket Type1’映射成数字1; ‘Supermarket Type2’映射成数字2; ‘Supermarket Type3’映射成数字3; ‘Grocery Store’映射成数字4。
1
2
3
4
|
Outlet_Type_mapping = {'Supermarket Type1':int(1), 'Supermarket Type2':int(2), 'Supermarket Type3':int(3), 'Grocery Store':int(4)}
data['Outlet_Type'] = data['Outlet_Type'].map(Outlet_Type_mapping)
data['Outlet_Type'] = data['Outlet_Type'].fillna(0)
|
7. 数据归一化
7.1. 产品重量’Item_Weight’
由前几步可看出’Item_Weight’分布较为均匀(5.5~21之间),故规范化时采用最小-最大规范化。
1
2
3
| Item_Weight_min = data['Item_Weight'].min()
Item_Weight_max = data['Item_Weight'].max()
data['Item_Weight'] = (data['Item_Weight'] - Item_Weight_min) / (Item_Weight_max - Item_Weight_min)
|
类似的适合数据归一化的还有:’Item_Visibility’, ‘Item_MRP’, ‘Outlet_Establishment_Year’, ‘Outlet_Size’,将这些变量也进行归一化处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Item_Visibility_min = data['Item_Visibility'].min()
Item_Visibility_max = data['Item_Visibility'].max()
data['Item_Visibility'] = (data['Item_Visibility'] - Item_Visibility_min) / (Item_Visibility_max - Item_Visibility_min)
Item_MRP_min = data['Item_MRP'].min()
Item_MRP_max = data['Item_MRP'].max()
data['Item_MRP'] = (data['Item_MRP'] - Item_MRP_min) / (Item_MRP_max - Item_MRP_min)
Outlet_Establishment_Year_min = data['Outlet_Establishment_Year'].min()
Outlet_Establishment_Year_max = data['Outlet_Establishment_Year'].max()
data['Outlet_Establishment_Year'] = (data['Outlet_Establishment_Year'] - Outlet_Establishment_Year_min) / (Outlet_Establishment_Year_max - Outlet_Establishment_Year_min)
Outlet_Size_min = data['Outlet_Size'].min()
Outlet_Size_max = data['Outlet_Size'].max()
data['Outlet_Size'] = (data['Outlet_Size'] - Outlet_Size_min) / (Outlet_Size_max - Outlet_Size_min)
|
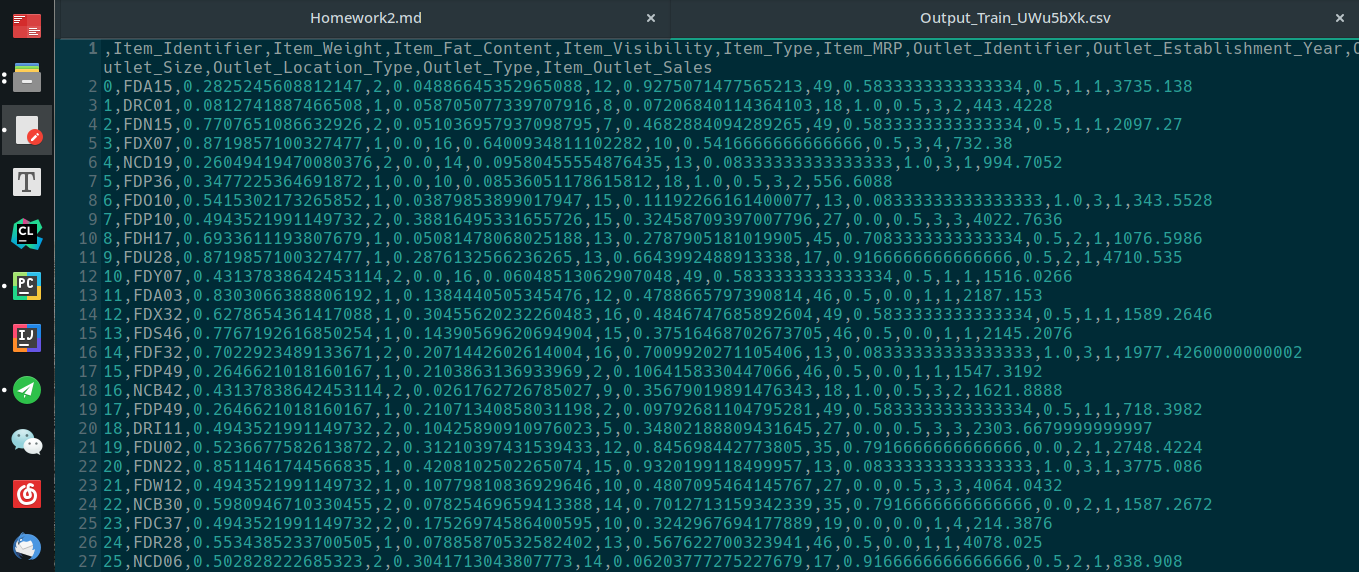
数据预处理后如下:
![“Train_UWu5bXk.csv”文件中的Bigmart销售数据预处理后]()